Java8 에 Lambda식이 새로 추가되었다. 람다 표현식에 대해서 잘 모른다면 그 표현식을 봤을 때 문맥을 이해하기가 쉽지 않다.
Java에서의 lambda expression을 어떻게 사용하고 왜 사용하는지 간단하게 정리를 해 보고자 한다.
람다식은 함수형 언어에서 선호하는 “정의”연산자 “->” 를 사용한다. 최근에 함수형 언어가 주목을 받고 있고, Java에서도 이를 지원하려는 움직임으로 보인다.
Scala, Erlang를 비롯한 함수형 언어라는 것의 의미를 먼저 살펴보자.
“함수형 언어”는 “명령형 언어”와 대조적인 관계에 있다. 명령형 언어에서는 상태를 바꾸는 것을 강조하는 것과 달리, 함수형 언어에서는 함수를 정의하는 것에 중점을 둔다.
명령형 언어에서 “a = 1” 이라고 선언을 하는 것은 “a라는 변수에 1을 담아라” 라는 의미이지만, 함수형 언어에서는 a 를 1로 정의한다는 의미로 사용한다. ( 그런 의미에서 R같은 언어에서는 대입 연산자를 A <- 1 이라고 표기하기도 한다)
대입과 정의가 비슷한 것 같아 보이지만 큰 차이가 있다. 대입은 프로그램의 수행중에 언제든지 값이 변경될 수 있고, 정의는 값이 변경될 수 없는 것을 의미한다.
즉 수학에서 f(x) = x + 1 이라고 정의된 함수가 있다면 입력값 x 에 대해 항상 x + 1 이라는 동일한 결과값을 기대할 수 있게 된다. ( 명령형 언어에서라면 변수의 값이 변경될 수 있으므로 같은 입력에 대해 결과값이 달라질 수 있음)
입력에 대해 결과값이 동일하다는 특징은 멀티 스레딩 환경에서 큰 장점이 있고(Thread safe), 이러한 특징은 손쉽게 병렬 프로그래밍을 할 수 있게 해 준다.
이런 특징이 멀티코어 프로세싱이 요구되고 있는 근래의 프로그래밍 환경에서 함수형 언어가 다시 주목을 받게 된 이유라고 볼 수 있다.
Java에서 Lambda 표현식을 사용하는 목적은, 예전처럼 변수를 직접 전달하여 그 값을 변경함으로서 흐름을 처리하지 않고, 행위 자체(Behavor Parameter)를 전달함으로서 함수형 프로그램이 지향하는 바를 얻기 위함이라고 생각된다.사실 이러한 목적으로는 기존에 이미 익명 클래스(Anonymous Class)를 통해 해결할수도 있었던 문제이지만, Lambda식을 사용함으로 해서 코드를 좀 더 깔끔하고 가독성 좋게 만들수 있게 된 것이다.
그리고 공식적으로 “자바는 함수형 프로그래밍을 지원한다!”라고 얘기하려고 한것이 아닐까 하는 생각도..
Lambda표션식이 생소한 이유중 하나가 바로 전에는 클래스가 없는 함수를 사용할 수 없었지만, 이 Lambda라는 놈은 클래스 없이 함수 구현체가 존재하기 때문에 자바에 친숙한 사용자일수록 처음에는 어색하게 느껴질 수 있을 것 같다.
“Java 에서 Lambda 표현식은 추상 메소드가 하나만 있는 인터페이스(Funtional Interface)를 익명 클래스 대신 구현할 수 있게 해 주는 방법” 이라고 할 수 있다.
추상 메소드가 하나만 있는 인터페이스들 중에 우리가 잘 알고 있는 것들이 있다. Java.util.Comparator , java.lang,Runnable 등이 그것인데 Comparator를 이용해서 lambda 표현식을 사용할때와 그렇지 않을 때 어떻게 코드가 달라지는지 살펴보자.
아래와 같이 User 클래스가 있다.
public class User implements Comparable{
private Long userId;
private String userName;
private String emailAddress;
private Date joinDate;
// getter &amp; setter 코드 생략
@Override
public int compareTo(Object o) {
User otherUser = (User) o;
if (this.userId > otherUser.getUserId()) {
return 1;
} else if (this.userId < otherUser.getUserId()) {
return -1;
} else {
return 0;
}
}
}
이 User 의 목록이 있을 때 userId를 기준으로 sorting을 하는 코드를 익명 클래스를 이용해서 만들면 아래와 같다.
userList.sort(new Comparator<User>() {
@Override
public int compare(User user1, User user2) {
return user1.compareTo(user2);
}
});
익명 클래스를 사용하지 않고 “Lambda”표현식을 이용하여 아래와 같이 코딩할 수 있다.
userList.sort((User o1, User o2) -> o1.compareTo(o2));
이렇게 Lambda 표현식은 함수의 argument로 전달이 될수도 있고, 아래와 같이 변수에 할당하는 것도 가능하다,
Comparator <User> userComparator = (User u1, User u2) -> u1.compareTo(u2);
userList.sort(userComparator);
아래 그림을 통해 Lambda 표현식을 어떻게 작성하는지 살펴보자.
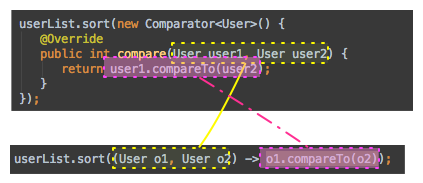
Lambda 표현식은 “->” 를 기준으로 왼쪽과 오른쪽으로 나누어 지는데,
왼쪽의 (User 01, User 02) 부분은 functional interface – 추상 메소드가 하나만 있는 인터페이스- 에 선언된 추상메소드의 argument 를 나타낸다.
오른쪽 부분은 추상메소드의 구현내용 – implementation-을 적어주는데 return type은 interface 의 추상메소드 signature를 따라 자동으로 결정된다. ( Runnable의 경우 void 임 )




