Logistic Regression 분석은 (예측)결과가 Yes(1) 이냐 No(0)이냐를 예측하기 위한 방법이다.
다시 말하면 결과 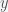
따라서 

Linear Regression 에서 사용했던 공식을 사용하면 결과값이 0보다 작을수도, 1보다 커실수도 있으므로, Sigmoid Function(Logistic Function)을 사용해서 결과값의 범위를 제한할 필요가 있다.
Sigmoid Function 을 아래와 같이 정의한다.
Logistic Regression 분석은 (예측)결과가 Yes(1) 이냐 No(0)이냐를 예측하기 위한 방법이다.
다시 말하면 결과
따라서
Linear Regression 에서 사용했던 공식을 사용하면 결과값이 0보다 작을수도, 1보다 커실수도 있으므로, Sigmoid Function(Logistic Function)을 사용해서 결과값의 범위를 제한할 필요가 있다.
Sigmoid Function 을 아래와 같이 정의한다.
선형회귀분석에서 cost function 

정규방정식은 
Feature 갯수(n)이 많게 되면 
하지만 feature 갯수 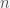

여러개의 변수(Multiple Variables)를 가지고 회귀분석(Linear Regression)을 할 때 변수의 스캐일이 너무 차이가 나면 Cost Function 
예를 들면 집의 가격을 예측하는 모델에서 가격을 결정하는 변수들로 크기(1000 ~ 2000), 방의 갯수(1~5), 사용년수(1~20)등을 생각해 볼 수 있는데 각각의 변수들의 스케일의 볌위가 많이 달라서 등고선을 그려보면 매우 좁고 길쭉한 모양이 나타나게 된다.
이럴때는 Mean Normalization 을 사용해서 변수의 범위를 
Nomalized된 변수 Z는 아래와 같이 구할 수 있다.
집가격을 예측하는 모델을 
집크기 

 이다.
이다. 이다.
이다.우리가 메일 서비스를 이용할 때 스팸 메일들이 자동으로 스팸함으로 이동되는 것을 볼 수 있다. 메일 서비스들은 도착한 메일이 스팸인지 아닌지 여부를 어떻게 판단해서 스팸으로 분류할 수 있는 것일까?
기본적으로는 “베이지안 추론“이라는 통계적 추론 방법을 통해 메일을 분류하게 되는데, 베이지안 추론이란, 사전확률을 통해 사후확률을 추론하는 것이다.
사용자들이 메일을 수신하고 스팸메일함으로 이동시킨 메일을 대상으로 “스팸으로 분류된 메일에 특정 단어들이 나타날 확률“을 미리 계산해 놓으면(사전확율), 어떤 특정 단어들이 나타났을 때 이 메일이 스팸일 확율(사후 확률)을 구할 수 있게 된다. 즉, 기존의 데이터를 이용해서 스팸메일로 분류할 방법을 학습(learning)시키는 것이라고 볼 수 있다.
Model Training & Test 용 데이터는 UCI – Machine Learning Repository (https://archive.ics.uci.edu/ml/datasets/Spambase) 에서 가져와서 사용한다.
사용할 데이터는 https://archive.ics.uci.edu/ml/machine-learning-databases/spambase/ 에서 확인할 수 있으며, spambase.zip 파일을 다운로드 받도록 한다.
spambase.zip 파일을 다운로드 받아서 압출을 풀면 3개의 파일을 확인해 볼 수 있다.
Spambase dataset 에 헤더정보가 없으므로 헤더를 구성한다.
load data file spam.base.df<- read.csv("./data/spambase.data",header=FALSE) # load header file # MakeHeader.py 로 spambase.names 에 있는 헤더 정보를 추출하여 headers 파일로 기록해 두었음. spam.base.header <- read.csv("./data/headers",header=FALSE,stringsAsFactors = F) # column 명에 특수문자가 포함되어 있으므로 make.names를 하지 않으면 as.formula에서 오류가 난다. headers <- make.names(spam.base.header[,1],unique=T) headers <- c(headers,"spam") names(spam.base.df) <- headers spam.base.df$spam <- as.factor(ifelse(spam.base.df$spam > 0.5, "spam","non-spam"))
spambase.names 파일에서 헤더정보를 추출하는 파이썬 코드
__author__ = 'yhlee'
import re
regex = re.compile('^(.+):\s+continuous\.')
f = open("data/spambase.names")
out = open("data/headers", "w")
for line in f.readlines():
# print(line)
m = regex.match(line)
if m:
# print line
header = m.group(1) + "\n"
out.writelines(header)
Machine Learning 모델을 선택해야 한다. 우리가 원하는 것은 특정 관측값(Observation)-수신한 메일-이 스팸 메일인지 아닌지에 대한 “분류”를 추정하는 것이다.
즉, 정량적 (Quantitive) 예측이 아니고 정성적(Qualitative) 예측을 해야 한다. 예측하고자 하는 값(spam/non-spam) 이 데이터에 이미 포함되어 있고, 그 값을 바탕으로 training을 할 것이므로 우리가 하고자 하는 분석은 Supervised Classification이라고 할 수 있다. Classfication Method에는 Naive Bayes, Decision Tree, Logistic Regression, LDA, KNN 등 여러가지 방법이 있으며,지금은 특정 관측값이 특정 분류에 속하게 될 확률을 추정해야 하고, 분류(Class)결과는 스팸/Non-Spam 두 가지의 (binomial) 결과가 있으므로 “Logistic Regression”을 선택해서 모델을 만들어 보겠다.
#fitting model
## Data Split to Train/Test
require(caret)
set.seed(1234)
trainIdx <- createDataPartition(y=spam.base.df$spam, p=0.75,list=F)
trainData <- spam.base.df[trainIdx,]
testData<- spam.base.df[-trainIdx,]
spamCols <- setdiff(colnames(trainData),list("spam"))
spam.fomula <- as.formula(paste('spam=="spam"',paste(spamCols,collapse=' + '),sep=' ~ '))
#모델 만들기
fit <- glm(spam.fomula,family = binomial(link='logit'),data=trainData)

Training Data 에 대한 Confusion Matrix 를 확인해 보면 accuracy가 92% 임을 확인 할 수 있다. Training Data로는 모델이 잘 만들어 진 것 같은데, testData로 내용을 검증해 보도록 하자.
5. Calculate Accuracy On TestData

TestData 에 대해서도 ConfusionMatrix를 확인해 본 결과 92%를 보여주고 있다. ROC Curve를 체크하면서 Threshold값을 조정한다면 더 정교한 모델을 만들수도 있다.
* GitHub Location


